Scrapy is a Python application framework for crawling web sites and extracting structured data. I challenged myself to see if I could write a web crawler that I could use to crawl this blog and scrape all of the post titles. Here’s the code I ended up using.
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://technicalagain.com/']
def parse(self, response):
for title in response.css('h1.title'):
yield {'title': title.css('a ::text').extract_first()}
for next_page in response.css('div.nav-previous > a'):
yield response.follow(next_page, self.parse)
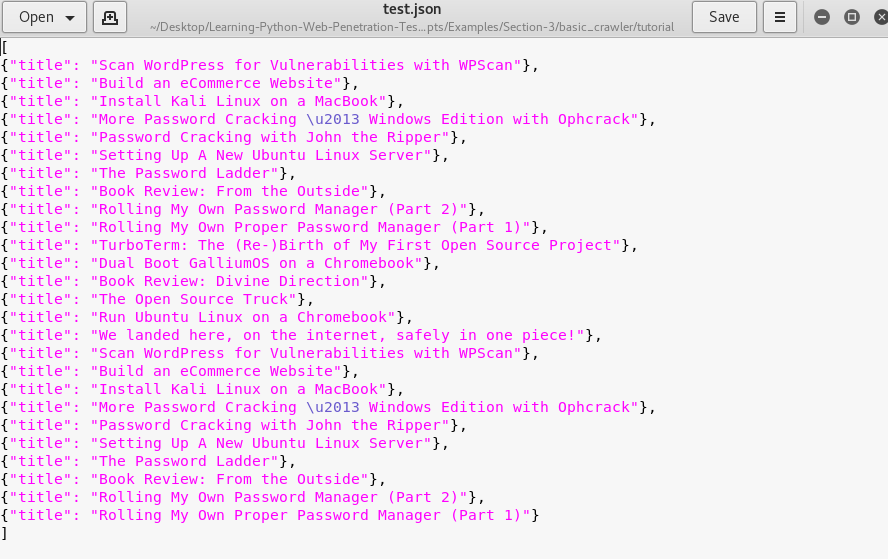
After writing the crawler above, one simple command then executes the crawler and writes the output to a .csv or .json file which is shown at the top of the post.
scrapy crawl blogspider -o blogs.json
There are duplicates due to the way the “previous” page renders in WordPress. I could put in some extra logic to remove duplicates but that can be a challenge for another day. This got the job done and is a nice utility that can come in handy.