I adding depth to an image and created a 3D look from a photo. This is another example of a project that can only be realized due to the amazing era we live – thanks to an amazing open source project on GitHub and the pay-as-you-go pricing on AWS.
Follow this post to add a 3D look to your own photos. You’ll need some familiarity with AWS EC2, AWS CloudWatch, and SSH/SCP to log in to your EC2 instance and move files back and forth. It took a lot of experimenting/trying/failing for me to get this project running smoothly. I’ve edited down the most direct path for you to recreate yourself. Post any questions in the comments.
Hardware, well software.
Software is eating the world.
Marc Andreessen
Ten years ago you would have had to buy or build a very expensive computer with a great graphics card(s) to create the 3D effect. In 2020, we lease our computing from AWS (or any public cloud provider of your choice).
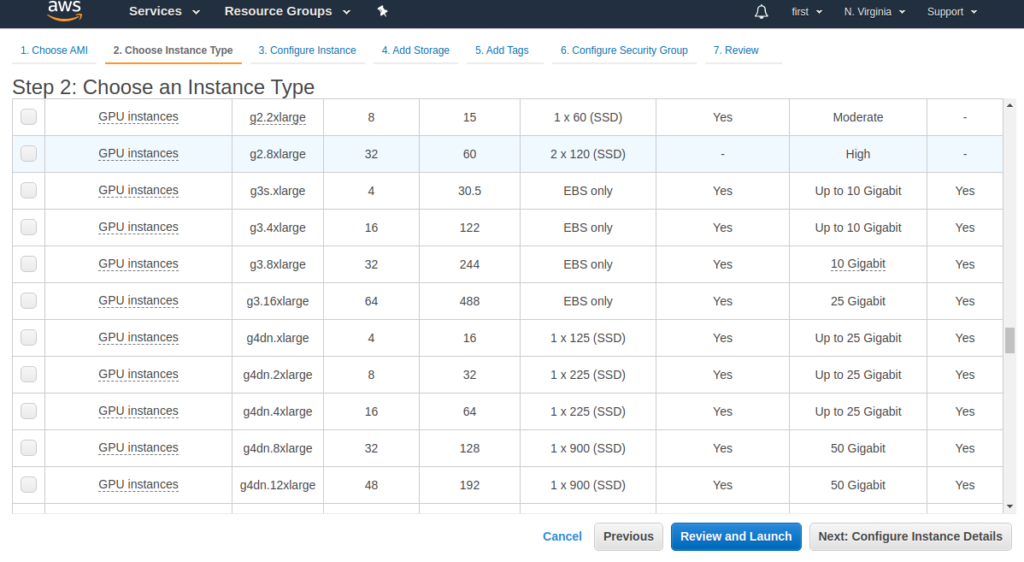
To start, create a new EC2 instance. I used the Deep Learning AMI from AWS and chose an extra large GPU instance (you have to scroll way down to find the GPU choices, so keep scrolling).
3D Photo Inpainting
Download the 3D Photo Inpainting project from GitHub and upload it to your brand new AWS instance. I believe the only dependencies you’ll need to meet are Anaconda and PyTorch. Pay close attention to the argument.yml file as it is a lot of configurations you can tweak. I will spare you from the hours of rendering issues I had due to underpowered and misconfigured EC2 instances.
Upload all the .jpg (not .jpeg unless you update the argument.yml file) photos you want to be converted to the /images directory. The software will kick out the 3D renders as .mp4 files in the /videos photo
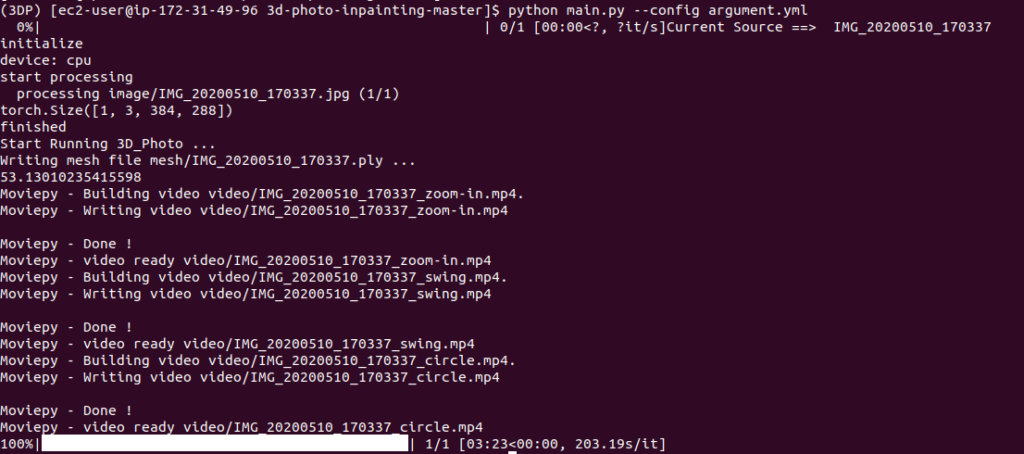
Then a few basic commands are all you need to get running: conda activate 3d and then python main.py --config argument.yml
This is what you should see if the images are being processed appropriately. It should take about 2-3 minutes per image.
The results speak for themselves – really amazing.
So what’s happening here?
We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that iteratively synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts when compared with the state-of-the-arts.
Saving Money
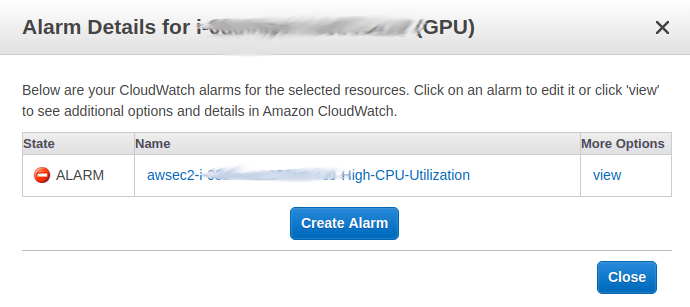
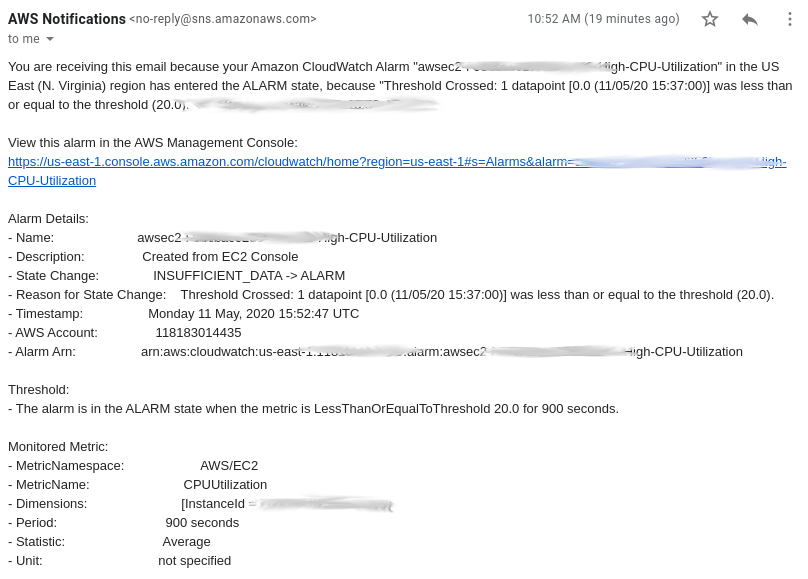
We definitely need to customize AWS to avoid this project costing us a lot of money in unused AWS EC2 run time. Remember, we’re not on the free tier with an extra large GPU intensive Machine Learning Instance. So, let’s add a CloudWatch rule and alert that shuts down our instance if the CPU is idle for 900 seconds (15 minutes).
Cost Details
This is going to cost me how much?! Not much, actually — probably less than $0.25 per image. As a best practice, we should shut down our unused appliances in AWS.
Thank you
Thank you to the four creators of this project: Meng-Li Shih, Shih-Yang Su, Johannes Kopf ,and Jia-Bin Huang. Very cool.
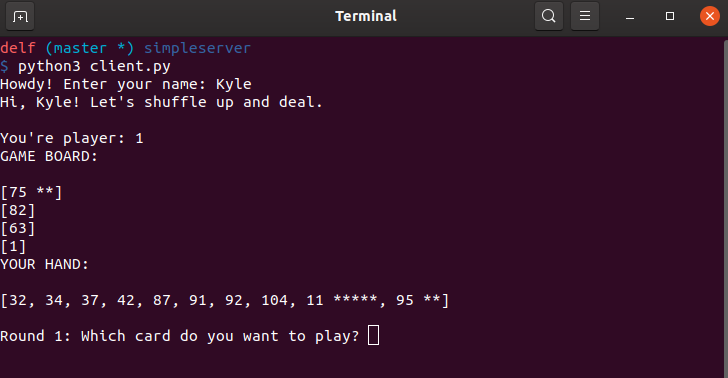
Slide 5 or 6 Nimmit! can be played with an actual card deck
My clone of Slide 5 written in Python
I almost gave up and quit on this project. I’m so glad I stuck with it because the results were so worth it.
After playing the Slide 5 card game I thought it would be a great game to clone into an online game that can be played with friends over Zoom during the pandemic lock in.
The game is called Slide 5, it’s a copy of the original game 6 Nimmit created in 1994! If you’ve never played before it’s really simple: Everyone gets 10 cards and then you have to play the next lowest card. Four rows build sequentially and if you lay the sixth card in a row or if you have a card lower than the last card in each row, you have to clear that row and take all the points.
My clone of 6 Nimmit! known as Six Minute.
How I Learned
I am in the final stages of completing a Udacity course on Python for Data Science. The course has been great. After completing the two main assignments for the course, I was looking for an opportunity to apply my new skills to a personal project. I watched this two hour seminar from freeCodeCamp Python Online Multiplayer Game Development Tutorial and decided 6 Nimmit! was the perfect game to code.
I felt especially motivated to apply my skills after reading a number of posts on reddit about people caught in Tutorial Hell and wondering if I, myself, was trapped in Tutorial Hell without knowing it.
What I Learned
The whole project is available on GitHub. Like all my code on GitHub, it could stand a good refactoring so try not to judge me too harshly on the repetitive code or the somewhat cryptic aspects that could use a good commenting. Here is what I learned, in brief:
How to build a server
How to connect clients to the server
How to store and retrieve objects on the server (Python Pickle package)
In depth understanding of the Pandas and Python data structures: dataframes, dictionaries, lists, tuples, series, and strings
In depth understanding of how to search and sort data structures
How to manage queuing the clients (everyone must be playing in the same round)
Game programming concepts: actions, penalties, scorekeeping. I think I could program another game with a different concept much quicker just because I have a framework for how to implement the major aspects of any game – the game “story arc” if you will.
I did a good job with continuous integration, and building and deploying working code. Every time I touched the project I completed the night with working code checked back into git. Little by little, I chipped away until I was totally done.
What I Struggled With
Lots. Let me just start with that. There were several moments that I was within an inch of quitting and got really down on myself. Here were some of the toughest challenges:
The very first data exchange between the server and clients took me a full night to get right.
Port management is not implemented very well. When the program ends, sometimes the operating system thinks the port is still in-use.
Keeping the clients in sync. For example, if one of the players got penalty points, only one client should update the scoreboard – not every client.
Data structure sorting. This was one of the most complex aspects of this game because so much has to be sorted: the game board, each player’s hand, the rounds, and the scoreboard. Additionally, the scoreboard is interwoven into the game interface. If you look at the image up above you see in my hand that the 11 is worth five points and 75 and 95 are each worth two. That was tricky to implement well in the terminal.
Controlling the use of random function on the server. While the server creates the gameboard and each player’s hand by creating a random numpy array and “popping” cards out of the deck into the hand, each client can’t receive a random hand or a random gameboard or we have pandemonium.
Obviously, I did not implement a traditional user interface.
The server does not have session management. If I kept going, I’d build a way to run multiple games simultaneously and keep track of which client is playing which game.
My testing and debugging practices are pretty rudimentary. It would be good continued learning to use pytest and improve my automated code coverage skills.
I have not deployed the app to the web. So another area for development would be to deploy in flask or django or deploy serverless on AWS, etc. Challenges for another day, I suppose
Would I Recommend this Project?
I would recommend a project like this to an intermediate programmer who has previous experience developing a complete application. This project really helped me level up my skills. I grew tremendously by sticking with it and getting done. However, there was a lot of frustrating nuance in this exercise.
Here’s one unexpected drawback of creating a game. After all the hours I poured into building the game and the increasing complexity in debugging and testing the game, I’m so sick of it I hardly want to play it. I hardly want to write this blog post about it. Hopefully, I’ll be up for the challenge because we’re hosting a family “game night” on Zoom on Sunday where we will play the game.
Every day right at 4pm when I should just about be getting hungry for dinner and losing motivation, I get a text message from My Future Self. The text message reminds me of my weight for today and compares it against all of the other 1048 entries I’ve logged on my scale the last decade.
My Future Self is smart enough to compare my weight to the previous day to give some encouragement or tough love. It tracks my distance to goal, too. The percentile is also dynamic so it will always be accurate even when more entries are added. Lastly, My Future Self keeps my a journal of my daily weight reading in a nice and tidy Excel spreadsheet.
This is part 2 to my previous post. Reading part 1 will help you to understand what I’m talking about here a little bit better. In part 1 I said: I am planning to tinker with the Withings API and try to create a more real-time “scorecard” to know what percentile I’m in and if I’m delaying (and ultimately defeating) the Dad-Bod date.
I did tinker with the Withings API and I thought it was painful. So I went down another path. I wrote a screen scraper in Python using the Selenium library to get my current weight from TrendWeight. I then add the weight to my weight journal, and send myself a text message. My Future Self runs as a cron job on a free-tier EC2 instance and uses the Amazon Simple Email Service (SES) to send the email.
I will eventually add it to my GitHub repo, but here is all the code for My Future Self (warning, it’s ugly, not refactored) if you’d like to meet your future self, too.
Here’s to defeating the Dad-Bod!
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from pyvirtualdisplay import Display
import datetime
from datetime import date
import pandas as pd
import pandas as pd2
from datetime import datetime
# headlessdisplay = Display(visible=0,size=(800, 600))
display.start()
#run pkill chrome to cleanup the process from the shellbrowser = webdriver.Chrome()
browser.get("https://trendweight.com/u/91a151bdce4143/")
#take a breathe allowing JavaScript to loadtime.sleep(2)
soup = BeautifulSoup(browser.page_source, "html.parser")
todays_weight = soup.findAll('td', attrs={'class':'measuredWeight'})[0].string
weight_today = float(todays_weight)
todayz_date = str(date.today())
#open master spreadsheet and append today's weight to the bottom.df = pd.read_excel("ThreeCleanSheets.xlsx")
df2 = pd.DataFrame({"weigh_in_date":[todayz_date], "weight":[weight_today]})
df = df.append(df2)
#more cleanup to remove dupsdf.drop_duplicates(inplace=True)
#Save the updated sheet.df.to_excel('ThreeCleanSheets.xlsx',index=False)
df3 = pd2.read_excel("ThreeCleanSheets.xlsx")
df3['Percentile_rank']=df3.weight.rank(pct=True)
#establish the index for our new weightx = (len(df3))-1#send the email logic is nextimport boto3
from botocore.exceptions import ClientError
# Replace sender@example.com with your "From" address.# This address must be verified with Amazon SES.SENDER = "My Future Self <kylepott@gmail.com>"# Replace recipient@example.com with a "To" address. If your account # is still in the sandbox, this address must be verified.RECIPIENT = "kylepott@gmail.com"# Specify a configuration set. If you do not want to use a configuration# set, comment the following variable, and the # ConfigurationSetName=CONFIGURATION_SET argument below.#CONFIGURATION_SET = "ConfigSet"# If necessary, replace us-west-2 with the AWS Region you're using for Amazon SES.AWS_REGION = "us-east-1"# The subject line for the email.SUBJECT = ""# The email body for recipients with non-HTML email clients.BODY_TEXT = ""weight_up_or_down = df3.weight[int(x)] - df3.weight[int(x) -1]
#173 is my goalhow_much_to_go = df3.weight[int(x)] - 173.# The HTML body of the email.if weight_up_or_down < 0:
enouragement = " Way to go, your weight is less than yesterday by " + str(round((weight_up_or_down),2)) + " pounds."else:
enouragement = " Get back at it, you can do it! Your weight was not less than yesterday. You went up" + str(round((weight_up_or_down),2))
BODY_HTML = "<html><head></head><body><p>Today you weigh " + str(round((df3.weight[int(x)]),2)) + " which is in the " + str(round((df3.Percentile_rank[int(x)]),2)) + " percentile." + enouragement + " Keep going! Only " + str(round((how_much_to_go),2)) + " pounds left to go to your goal!</p></body></html>"# The character encoding for the email.CHARSET = "UTF-8"# Create a new SES resource and specify a region.client = boto3.client('ses',region_name=AWS_REGION)
# Try to send the email.try:
#Provide the contents of the email. response = client.send_email(
Destination={
'ToAddresses': [
RECIPIENT,
],
},
Message={
'Body': {
'Html': {
'Charset': CHARSET,
'Data': BODY_HTML,
},
'Text': {
'Charset': CHARSET,
'Data': BODY_TEXT,
},
},
'Subject': {
'Charset': CHARSET,
'Data': SUBJECT,
},
},
Source=SENDER,
# If you are not using a configuration set, comment or delete the# following line#ConfigurationSetName=CONFIGURATION_SET, )
# Display an error if something goes wrong. except ClientError as e:
print(e.response['Error']['Message'])
else:
print("Email sent! Message ID:"),
print(response['MessageId'])
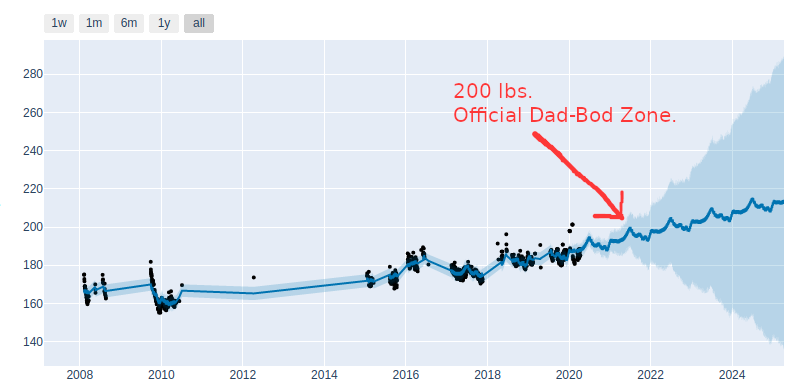
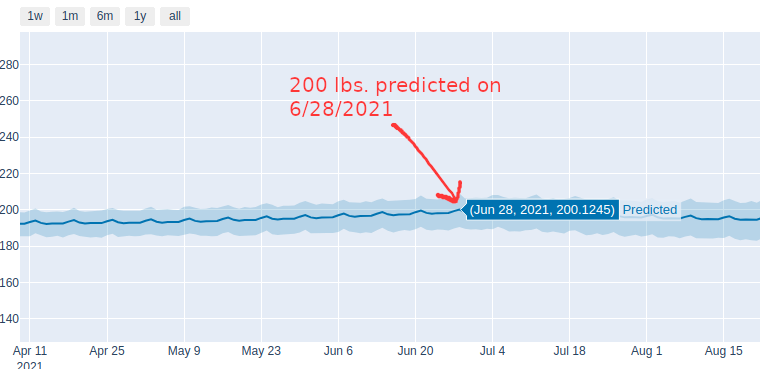
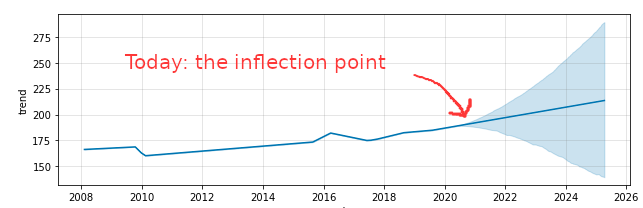
I stepped on the scale more than 1000 times in the past decade and then used Facebook’s predictive modeling framework, Prophet, to see what I will weigh in five years if I don’t make changes. At 5’9″ I’ll officially have a Dad-Bod when I pass 200 lbs. on June 28, 2021.Note: I couldn’t help myself from using a click bait headline. The only thing Facebook has to do with this post is I used an amazing open source prediction library they created called Prophet.
Like most people in America, I have the habit of occasionally stepping on the scale. Like most people in America, that scale has been increasing since 2008. I stepped on the scale over 1000 times in the last decade. I gathered up all this data and learned somethings about myself.
To continue building my Data Science skills, I used Python to wrangle and clean the data, visualize the data, predict likely and possible outcomes, and drew conclusions about my habits. To keep things short, I’ll jump right to conclusions *that apply to me* then go in depth below on analysis techniques, explanations, and next steps.
Conclusions
Weight gain is an insidious monster.
Weight gain happens when we’re not looking (not stepping on the scale each day).
Weight gain is seasonal.
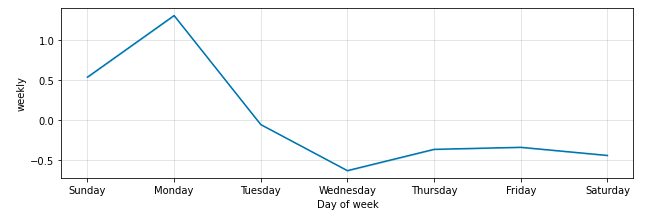
Wednesday is a pivotal day in the week for weight loss progress.
I control my own destiny in the future. Update, in Part 2, I create a tool, My Future Self, to defeat the Dad-Bod
Wrangling the Data
Since 2008 I used four different tools to track my weight: Hacker’s Diet Online, Weightbot (app retired, all data lost), MyFitnessPal, and TrendWeight. I was able to export, clean, and concatenate data from three of the four. Here’s the Python code I used to get a two column .csv with dates on the left and weights on the right. Update: see the GitHub repository below for the code. No judgment please, the code is not clean and could stand a good refactoring.
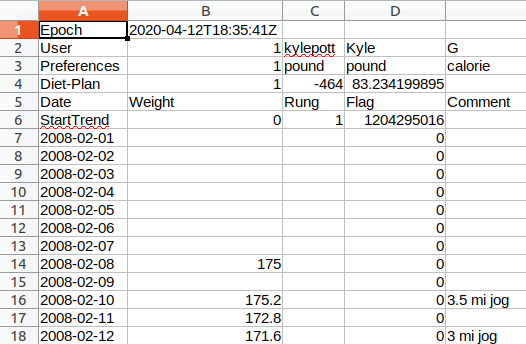
I started with the Hacker’s Diet data which was very poorly formatted (see the image below). Then I repeated the process with MyFitnessPal, which was better and finally TrendWeight which was in the best shape. TrendWeight is my current favorite tool for tracking weight as it has a tremendous amount of detail and also integrates seamlessly with my Withings wifi scale. The first part of this project was an art of renaming columns, removing null entries, removing repeating column headers, and selectively converting kg to lbs for the month or so I thought logging my weight in kgs would somehow be helpful (it wasn’t). Then I concatenated everything using an outer join to make sure I had only unique data and nothing repeating.
This is an ugly csv file.
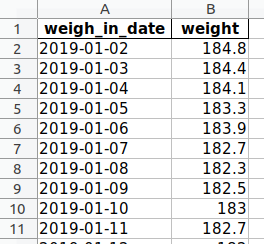
Now, we have a nice looking and easy to manage csv file with 1048 entries that we can work with for analysis and visualization.
This is a nice csv file.
Update: Originally, I included all the Python code in this post, but it got pretty lengthy. Instead, I created a new open source GitHub project if you want to download my work and use it yourself (GNU General Public License v3). Here is a direct link to a PDF of my Jupyter notebook if you’d like to follow my work step by step.
Describe the Data
After getting everything cleaned up, I started with a few basic techniques to learn more about the data.
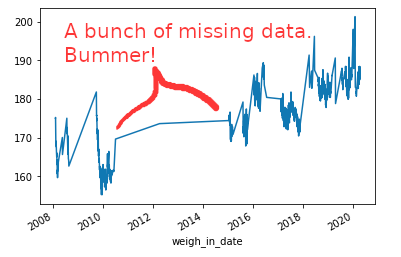
Basic describe() function in Python gives us a good summary of the data. I binned the weights into tenths to help see the spread and give myself some targets for improvement.I lost a lot of data from 2011 – 2015 which sucks. But, you don’t have to be a data scientist to mentally add a best fit line and see we have a problem. The weights are going up and to the right.
Before coming down on myself too harshly, there are two bits of qualitative information to keep in mind. This data set covers 12+ years of my life from ages 23 to 35 and ranges 46.1 pounds from a low of 155.2 to a high of 201.3.
1.) I’ll start with a bit of an anecdotal observation. I think there is something to consider that a 23 year old male, me, just finishing college and getting started in the real world may not be done growing. I would imagine if we studied populations, very few people would weigh the same at 30, 40, 50+ as they did at 23. That’s not to suggest that everyone becomes more unhealthy as they age (adding body fat), but just an acknowledgement that a low weight I achieved in 2009 of 155 lbs. at age 24 may not be possible to achieve ever again. It just may not be possible. (more on this below).
2.) I started lifting weights regularly at the end of 2011. Unfortunately, the first four years of data from when I started lifting weights is gone and unrecoverable. However, I think it is fair to say that at a very conservative rate of growth, I could add 1-2 pounds of muscle every year. That might make a new plausible low weight for me to be 164-173. That assumes adding 1-2 pounds of muscle per year and that would be a *low* weight between the 10th and 30th percentiles of all weights I’ve ever weighed in my entire adult life.
Note: when I say I started lifting weights, intensity, effort, and consistency factor in. I competed in a powerlifting meet and achieved a 1000+ lb. total (bench, squad, dead lift). I’m not an elite athlete, but just to put in context when I say I might be able to add 2 pounds of muscle per year, it’s the backing to suggest this is plausible.
Thank you actual Facebook for helping me unearth this gem.
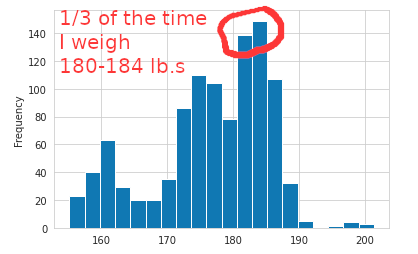
With such a wide range of possible weights, I thought it would be helpful to bin them and drop the data into a histogram. I learned that I weigh 180-184 nearly 1/3 of the time. This is good to know to help with the mental anguish of weight loss. Shouldn’t I weigh 155-160?! Actually, no I shouldn’t, because I almost never weighed that much (less than 6% of all weigh ins in 12 years). Also, it helps with setting a near term goal: get to a weight of < 180 and I’m already in the 50-60 percentile. Then get to 178 and I’m in the 40%, 175 and I’m in the 30%. We’re not talking huge numbers of pounds to lose here.
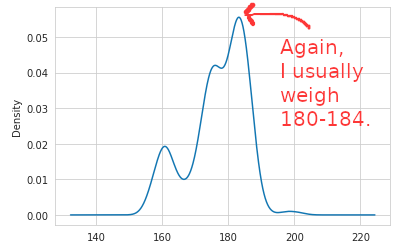
We can explain this concept in another way by showing a density chart. My greatest densities are in alignment with what we just discussed 180-184 lbs. then 179 lbs.
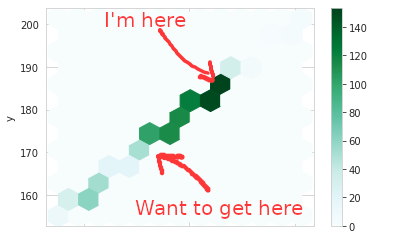
Another way of showing the same concept using hexbins. Where I am and then where I think I’d like to get to for the long haul.
Cycles of Weight Gain and Loss
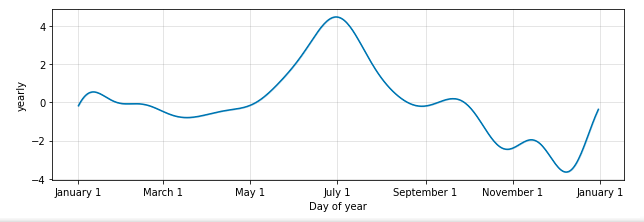
Whereas most people try to look better in their swimsuits, apparently I prefer to look thicker in my swimsuit. You know, to fill it out, I guess. After a modest downward tick after New Years, you can see a climb up that peaks around the 4th of July and then a steady weight loss through the end of summer, start of Fall, and just before the holidays. Then about a five pound weight gain through the holidays.
The Facebook Prophet library makes analyzing seasonality incredibly easy!
When we look at “seasonality” applied to each week, we learn more helpful insights about my habits. In order to reverse the trend here, I need to do better on Wednesdays and soften the weekend peaks. We have a bad data problem shown here. I have recorded very few weigh ins on Saturdays so that day of the week is not well represented. Presumably, because I eat a lot on Friday nights and I’m not all that interested in stepping on the scale at the start of the weekend. Another “now” habit to establish.
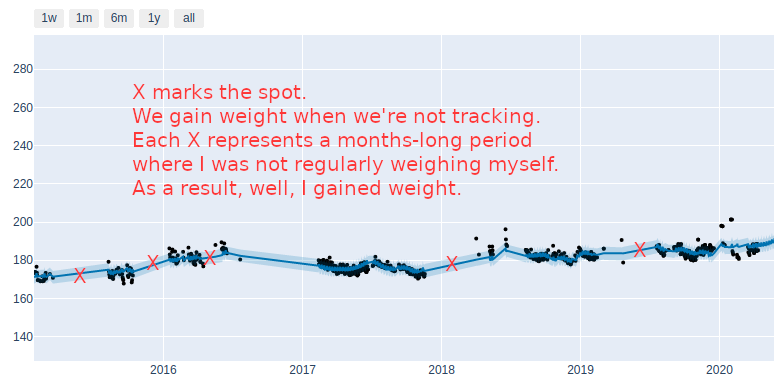
We Gain Weight When We’re Not Looking
There are a few exceptions, but unsurprisingly, long periods where I was not stepping on the scale resulted in prolonged increases in my weight.
Red Xs mark long periods where I was not weighing myself and led to weight gain. Notice each cluster of black dots shows a distinct downward trajectory. In other words, stepping on the scale each day is enough to suggest I care about my health and results. It’s not so much about having a perfect nutrition plan, but simply stepping on the scale each morning is going to help me focus on making better choices throughout the day and ultimately lead to results. Consistency matters – no surprise there.
Recipe for Success
I loved the book Atomic Habits. One of my top 10 favorite books. Author, James Clear, makes the case that to successfully establish new habits we need to break the trigger action down to the simplest, lowest level. Following that advice, here’s what I learned from this project that I will put into practice.
1.) Step on the scale every day. Even if I know I’m not going to like the results.
2.) Wednesdays are the day I will be most focused on my nutrition because it’s sets the tone for the week. No cheat days on Wednesdays.
3.) Set small goals, and keep working my way down the ladder. For me that means get to the next bin: 90th percentile is 185, 80th is 184, 70th percentile is 182, etc. until I arrive at the target range which is the 30% or 173. Update: Read Part 2 to see the system I set in place with a daily text message to remind me and give some encouragement.
Final Thoughts
We control our own destiny – I meant for this post to be equally heavy on accountability and inspiration – we can achieve anything we set our minds to. Take a look at this last visual and look how the prediction splits toward either success and failure. There’s a quote I like that captures it:
One critique of my analysis is that weight (alone) does not tell the whole story (lean mass vs. fat mass). This is true and one of the reasons I love using the Withings scale with TrendWeight is that I have detailed lean/fat mass readings going back to 2018. I may dive into this in more detail, but I am somewhat skeptical about the accuracy of these readings. Nevertheless, it’s something to consider exploring.
I am planning to tinker with the Withings API and try to create a more real-time “scorecard” to know what percentile I’m in and if I’m delaying (and ultimately defeating) the Dad-Bod date. Update: This is done. Read Part 2.
If there’s enough interest, I’ll consider creating a web app that you can upload your own MyFitnessPal data and then get a similar set of visuals about your own data.
Thank you to the Facebook engineers that created Prophet. I really enjoyed using it.
Update:I’m bummed that the Big Ten and NCAA tournaments were canceled. Subsequently, my trip to Vegas was canceled and therefore, there’s really no point in my model – at least for 2020. That said, it’s still a great learning opportunity and I finished the work, which is included below. The work here can serve as a good starting point for the 2021 tournamentwhere I expect my Illini will be a three seed and at least co-champions of the Big Ten.
Reminder, here’s part 1 of the series. We draw out our hypotheses to get the following variables correlated with winning a first round tournament game.
For the first draft of the model, we are going to try to keep things simple and just pick adjEM and Quad1 Wins + Attempts margin. This way we avoid sampling bias by not over-indexing the model by stacking variables that all show a modest correlation when independently measured. Example: we shouldn’t pick adjusted efficiency, defensive efficiency, offensive efficiency, and efficiency ranks because these all make up the adjEM (well, rank is derived from the adjEM so it’s also not a great choice). If a team has an advantage in efficiency margin and Quad1 Wins + Attempts Margin then we are going to place the bet. To keep things simple, let’s assume everything is a $50 bet.
Build the model
Let’s write our model in Python. First we split each game into a couplet – so our DataFrame now has one row with two teams on each line. Then, we convert our data to integers for easier comparison and then we compare the head-to-head adjusted efficiency rates for each team as well as the quad1 wins + attempts on a head-to-head basis. If a team has a better adjusted efficiency margin and more quad 1 wins and attempts, we place the bet! Surely, this will make us millions. We’ve done it. We beat Vegas! Not so fast…
import pandas as pd
import numpy as np
df = pd.read_excel("couplets2.xlsx","Sheet1")
#after import convert float to integers for easier comparison
df["AdjEM"] = pd.to_numeric(df["AdjEM"])
#compare the head to head adjusted efficiencies
df['team1_efficiency_is_better'] = np.where((df['AdjEM'] >= df['adjem2']), 1, 0)
df['team1_more_wins'] = np.where(df['wins'] > df['wins2'], 1, 0)
#compare the head to head quad1 wins + attempts
df['team2_efficiency_is_better'] = np.where((df['AdjEM'] <= df['adjem2']), 1, 0)
df['team2_more_wins'] = np.where(df['wins'] < df['wins2'], 1, 0)
#identify which bets to place
df['make_the_bet_on_team1'] = np.where((df['team1_efficiency_is_better'] + df['team1_more_wins'] >= 2), 1, 0)
df['make_the_bet_on_team2'] = np.where((df['team2_efficiency_is_better'] + df['team2_more_wins'] >= 2), 1, 0)
print(df)
Code language:Python(python)
Test the model
Let’s run the model blindly against the actual results of the 2019 tournament and see the results we get. 18 bets placed ($900). Overall record: 12-6. Hey, that’s not too shabby! Unfortunately due to the way the 2019 tournament was seeded, we ended up placing no bets on any underdogs according to the Money Line. Overall, we made -$213.45 or -23.7% return on investment. Yikes! If only it was as easy as correlating the variables, writing a model and then, beating the Vegas odds. Remember, the House always wins. I can just see myself now justifying, saying, “well I just came to Vegas to have fun with friends, so losing $200 is not that bad.”
Baseline our results
Let’s take a step back and build a baseline model to compare our results against. We can see that seed has the second strongest correlation of our set of variables. Let’s compare how we would have done if we just went straight chalk and picked the teams with the lower seeds. Straight chalk, homie!
26 bets placed ($1300). Overall record: 14-12. We placed no bets on any upsets according to the Money Line. Overall, we made -$469.59 or -36.12%. Ouch! So at least my first model is better than just picking the team with the lower seed! I’ll take 13% better return on investment than just picking the lower seed – at least for a first crack!
After doing some data snooping, what if we trim the median, using a 75% interval and try to go totally “anti-chalk” by betting every underdog three seed and above? 22 bets placed ($1100). Overall record 12-10. All 22 bets were placed on underdogs and we won 10 of them. Overall, we made $400.40 or +36%. Great result, but not so fast! This approach is really not based on our model at all and is likely representative of a variety of sampling biases like the vast search effect as well as target shuffling. Basically, by repeatedly running models, cherry-picking data, and changing the target outcome, we find what appears to be a solid approach only for it to fail, catastrophically, when run under real conditions.
If you torture the data long enough, eventually it will confess.
What a bunch of statisticians supposedly say at happy hour.
Said more simply, the fact that the 2019 tournament had 10 upsets in the first round absolutely must be drawn out to a bigger data set to see if this result happens every year (it does not). Just checked the data and going back to 1985, when you trim the median like I did you see somewhere around 6, maybe 7 upsets on average in the first round per year. Unfortunately for my hypothesis, many of these upsets took place by the team with the lower adjusted efficiency and a lower quad 1 wins + attempts margin. As the saying goes, that’s why they play the game and why I suck at data science so far.
Wrapping it all up
So was my model effective? That depends. Do you like to make money when you gamble? Kidding aside, I think a model that was 13% more effective than baseline is a great starting point. But, yes it did lose money. Overall, I’m pleased with my effort, learning, and setting a foundation to improve on next year.
Improving next year
For improving on this model next year we should look to expand the amount of data in the model by looking at games from more than one tournament year. Additionally, we should look to improve the value of the adjusted efficiency and the quad1 wins + attempts variables by more heavily weighting the performance of the teams within the last month or two leading up to the tournament. The way college teams play in the beginning of the year is rarely indicative of how they play at the end of the year. Another good area to focus would be splicing the quad1 data even further. As an example, we can split the quads into eighths by breaking each quad into a “good” game (top half of the quadrant) and a “bad” game (bottom half of the quadrant).
Overall, this was a good and fun first learning project–even though the tournament was canceled. So much learning is in front of me.
“Usually the team that scores the most points wins the game.” – John Madden
Update: If you’d like to jump right to part 2 of this series you can do so here where I turn the regression analysis into a really basic data science model.
I’m taking the first steps of an 18-24 month journey with a beginner’s mindset to establish and grow my data science skills. What better way to begin to learn new skills in March than by applying them to March Madness?!
I’ve learned the framework for any good data science problem looks something like:
What’s the question we want to answer?
What is the training data set we’re going to use? How are we going to wrangle the data?
Exploratory data analysis including identifying relationships.
In this post, I’ll tackle the first four steps of this framework and share a few conclusions. I’ll also note right up front, while I’m beginning to dive into the technical stack that helps enable data science (Jupyter, Python, Pandas, Numpy, Pyplot, and Seaborn), the problem I tackled could be better classified as a standard “statistics” problem. It’s definitely a “small data” problem and I haven’t built the model yet – so I don’t think it’s accurate to claim this work as anything resembling “data science” yet.
I’m just starting out on this journey. There’s probably so much wrong with my thinking here. I would love those with more experience to offer criticism and point out the flaws in my thinking and application. I tried not to over-complicate the technology, so I used Excel. The data set could be loaded into a structured database or something even more complex – but why? Let’s keep things as simple as possible. For the modeling portion I may load it into MySQL or Postgres.
What’s the problem we want to tackle? How do we pick round 1 tournament winners? Why do we only care about round 1? Simple. I’ll be in Las Vegas actually betting on the first round games. So let’s find an asymmetric advantage, put it to use, and benefit from it! That’s the goal any way. Here are a few of my starting hypotheses:
In 2018 the NCAA retired the strength of schedule measure, known as RPI, and replaced it with NET rankings. The basis of NET rankings is bucketing wins into quads. The NET rankings take into account, game results, strength of schedule, game location, scoring margin, offensive and defensive efficiency, and quality of wins and losses. I won’t explain all of this here, but my hypothesis is: does playing in and winning quad 1 games correlate with winning a first round tournament game? This hypothesis was born out of frustration seeing a team like Dayton ranked in the top 5 nationally, but having played in only three quad one games and my beloved Fighting Illini playing in 15+ quad 1s and being ranked #23. I’m just not convinced that teams that play in very weak conferences should be in the national conversation, sorry Dayton. P.S. Dayton’s strength of schedule ranks 94th nationally. Dayton’s non-conference strength of schedule ranks 185th nationally. Sorry, that’s not a #3 ranked team in my book.
I dove into the quad 1s and it got me thinking, what factors correlate strongest to winning in the first round? What’s the strongest correlation I can find? Offensive rebounds? Turnovers? Defense? Three point shooting? Getting to the line and actually hitting free throws? I ran these all down!
Okay, let’s get to it!
What’s the training data we’re going to use?How do we wrangle the data? We’re going to grab and collate data from a variety of sources – let’s start by grabbing the 2019 NCAA first round tournament results. Let’s also grab the Vegas Money Line odds for these games. I like to bet the Money Line – just picking winners and losers – I don’t mess with the spread. We’ll also grab the quad 1 results for each tournament team last year. We’re going to grab the KenPom.com data and with a premium subscription from KenPom, we’re also going to grab the “Four Factors.” I won’t exhaustively describe all these factors, but suffice it to say, that I hopped right on the shoulder’s of giants and grabbed the absolute cutting edge of basketball stats that I could find:
Adjusted Efficiency Margin is the difference between a team’s offensive and defensive efficiency. It represents the number of points the team would be expected to outscore the average D-I team over 100 possessions.
Effective field goal percentage is like regular field goal percentage except that it gives 50% more credit for made three-pointers.
Turnover percentage is a pace-independent measure of ball security.
Offensive rebounding percentage is a measure of the possible rebounds that are gathered by the offense.
Free throw rate captures a team’s ability to get to the free throw line.
Quad 1 Wins wins over “good” teams – top 30 wins at home, top 50 wins at a neutral site and top 75 road wins. We test for wins, attempts, wins + attempts, winning percentage, win margin, and win + attempts margin.
There are breakouts for offensive efficiency, defensive efficiency and the “Four Factors” also apply to offense and defense. Additionally, we include national rankings for each category as well as quad 1 data. All in, we’re looking at 37 different factors to determine correlation.
Let’s write some code!
I used Pandas to outer join data from three different spreadsheets matching the data according to team name. This was very, very awesome and easier than collating in Excel directly and much faster than doing it by hand. The code below reads in a spreadsheet matches the team name and spits out a new spreadsheet with all the data matched up. Sweet!
Edit: I should have done either a left join or an inner join. The outer join included everything that matched and everything that did not match. An inner join or left join would have just included the data about the rows that matched. Not a big deal, but a learning point that would have resulted in data wrangling and cleanup time for me.
Exploratory data analysis and descriptive statistics
I love how easy Pandas makes it to analyze and describe the training data! Early in this project I was pulling everything into arrays and using NumPy to find the coefficient correlation manually of each variable! Then I switched to Pandas and basically did all the manual work instantly. Here’s the old way where I was correlating every variable against the round 1 wins for each region.
Then I did a little bit better by using Pandas to read in entire columns of data instead of manually creating the arrays.
import pandas as pd
import numpy as py
df = pd.read_excel("ncaa.xlsx","Sheet1")
q1winsplusattempts = df['2019_quad1_wins_plus_quad1_attempts']
r1win = df['2019_round1_win']
py.corrcoef(r1win,q1winsplusattempts)
Code language:Python(python)
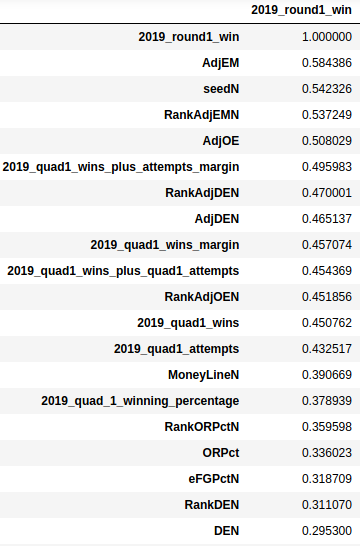
Finally hit it out of the park by using Pandas to import and native functions to correlate and sort according to strongest correlation!
df5 = pd.read_excel("Outerjoin2.xlsx", "Sheet1")
df6 = df5.corr()
#sort by absolute value to establish ranking by highest correlation
df6.abs().sort_values(by=['2019_round1_win'], ascending=False)
Code language:Python(python)
Now we have the basis on which we can build our model! For the next steps, we’ll use our Money Line odds to apply the variables that have the highest correlation with round one wins to build a model to maximize our chance of guessing the round 1 winners correctly in this year’s tournament. We’ll also calculate our expected winnings (or losings). But before I get to the conclusions, here are a few critiques.
Critiques
With the NCAA switching to NET rankings, this becomes an incredibly small training set. We essentially have only one year of tournament wins with which we build our training set. This will get better over time, but what we’re essentially saying is X variable has a strong correlation with winning last year’s first round game.
Correlation can be used for predictive purposes, but you know correlation doesn’t equal causation thing. For example, the tournament seeding awarded on Selection Sunday has the second strongest correlation of the 37 variables we looked at. Just getting a higher seed doesn’t cause you to win tournament games. I’m also very skeptical of that variable because I know how manual the selection and seeding processes are. I also think the 1 vs. 16, 2 vs. 15 matchups so rarely result in an upset that they overly sway the seeding variable, so we’re going to avoid using seeding in our final model.
Second critique here, and I’m not sure what to call this, but I may be overloading the correlation of the wins + attempts variable and some of the other variables. As an example, what I mean is adjEM takes into account adjOE so we wouldn’t necessarily want to include both in the final model. I’m going to try to keep the model as simple as possible and not “over index” it with repetitive variables.
Third, this a shallow data pool. Sure, I could very easily pull in data for each year going back to 2002, however, I’m not sure I see a meaningful enough return on the effort that would take. Are we really going to unearth a new variable in 17 years worth of games that we wouldn’t see in one year, about 35 games? I suppose it’s possible but I’m not willing to invest the time.
Lastly, remember, Vegas always wins. Any advantage we’re going to find here is going to be modest. Vegas adjusts the money line constantly — all the way until the game starts — that way they are hedging against any loss. Games that are so lopsided (1 vs. 16 matchups) usually don’t even include a money line because there’s no way for Vegas to be profitable on it. The house makes, sets, and then resets the odds in their favor! We analyzed 38 variables through occasional effort in the evenings. In Vegas you’re going up against full-time, highly experienced statisticians that include 2000+ variables and they run thousands of models to simulate each game. At the end of the day, what we’re doing is just a little more informed guessing. The house always wins. We’re left with Lady Luck. At least we feel better losing our money because we tried hard. Good try, good effort.
Conclusions
There does appear to be something to the old adage, “being battle tested and battle proven.” Playing in more quad 1 games (and winning them) does give you a better chance at winning a first round tournament game.
Adjusted Efficiency Margin looks to be the best single predictor of tournament success. No surprise here as this measure is so dang comprehensive, factoring in: pace, turnovers, shooting effectiveness, rebounding, free throws, fouling, and just about everything you can think of.
Defensive may win championships, but according to our analysis, offensive is a better predictor of first round tournament success. If in doubt, go with the team that gets more buckets!